

前言
Langchain 是一个大语言模型(LLM)应用开发的框架,提供了 LLM 开发中各个阶段很多非常强大的辅助工具支持。对于进行 LLM 开发是必不可少的工具库。
本文将通过一个实际的开发例子来入门 LLM 开发基础工具链,并实现 langchain.js ChatModel 接入火山引擎大模型和基于 langchain 工具链实现一个简单的 CLI 聊天机器人
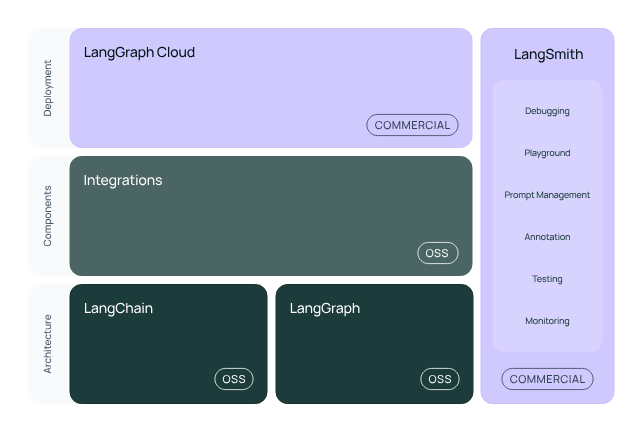
ChatModel & LLM
目前国内外有各种各样的大模型,而 langchain 作为一个通用 LLM 应用框架,它本身是和具体大模型无关的,是可以和任意模型进行交互的。要实现和模型的交互就要实例化使用相应的模型。
一个以 OpenAI 为例子则是安装相应的@langchain/openai和配置相应的 API key 进行使用即可
1 | import { ChatOpenAI } from '@langchain/openai' |
由于 langchain 目前没有提供火山引擎模型的集成,这里我们需要实现一个对于火山引擎大模型的集成
在 langchain 中有两个组件都可以实现模型的对接分别是 ChatModel 和 LLM。
其中 LLM 实现由于只能接收字符串作为输入输出,对于新模型目前已经不再推荐使用。而是使用 ChatModel的实现来替代,ChatModel 是可以使用一系列消息作为输入并返回聊天消息作为输出的语言模型。支持将不同的角色分配给对话消息,有助于区分来自 AI、用户和系统消息等。
因此我们这里使用ChatModel来实现火山引擎的接入
火山引擎大模型开通
目前火山引擎对于每个大模型都提供了 50 万的白嫖 token 和部分模型的免费试用
创建接入点
完成相关基础的注册认证后,前往火山方舟在线推理新建接入点
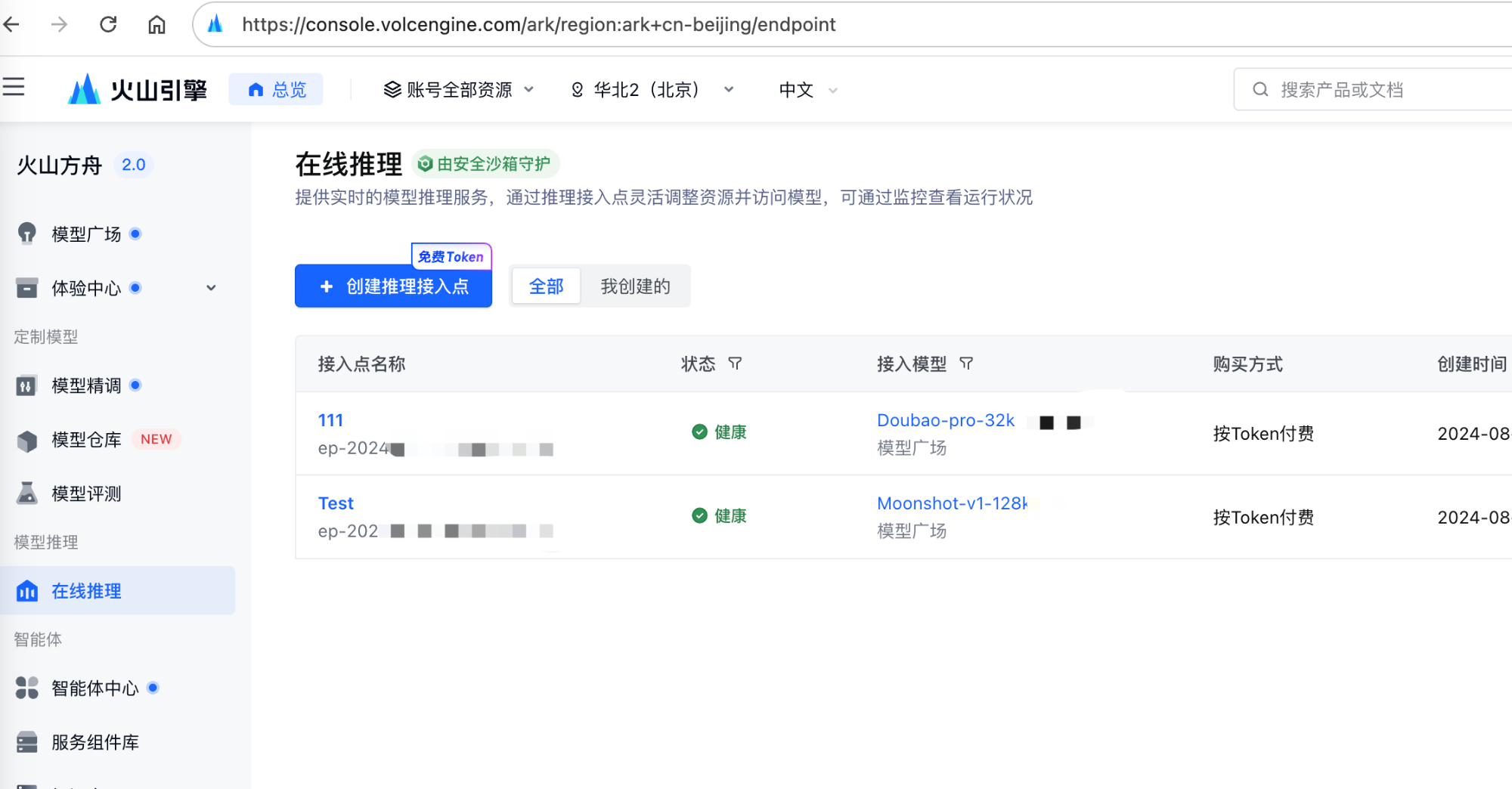
记住我们的接入点ep-xxx作为下面初始化的 model参数
创建 API key
前往 API key 管理 创建 API key
实现自定义 ChatModel
要实现 langchan 中的大模型对接需要实现SimpleChatModel基类,主要实现以下 3 个方法
abstract _call(messages: BaseMessage[], options: this["ParsedCallOptions"], runManager?: CallbackManagerForLLMRun): Promise<string>;
大模型调用,传入对话消息返回大模型返回的字符串
abstract _llmType(): string;
返回模型名称,便于在日志中打印调试
_streamResponseChunks(_messages: BaseMessage[], _options: this["ParsedCallOptions"], _runManager?: CallbackManagerForLLMRun): AsyncGenerator<ChatGenerationChunk>;
大模型交互时流式输出支持,调用 model.stream等方法时会调用该实现
因此对接大模型的实现思路也是比较清晰,主要就是实现_call和_streamResponseChunks根据接收的参数来根据火山引擎的 Open API 文档进行调用
主要实现
- 参数和类型定义
我们对外导出ChatVolcengine类作为模型对接使用。按照火山引擎的文档将相关的模型参数作为构造类的入参
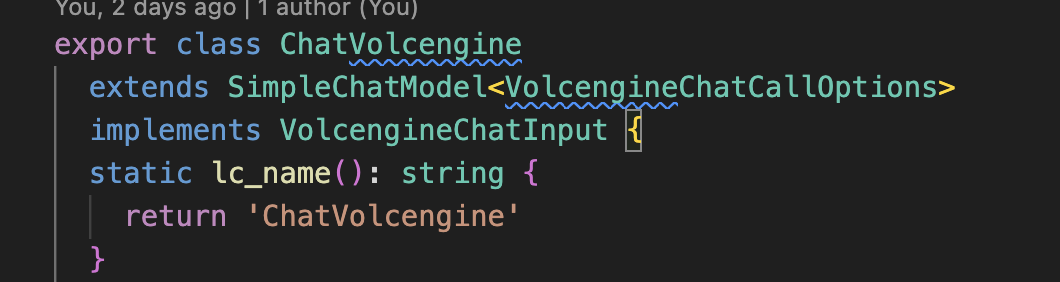
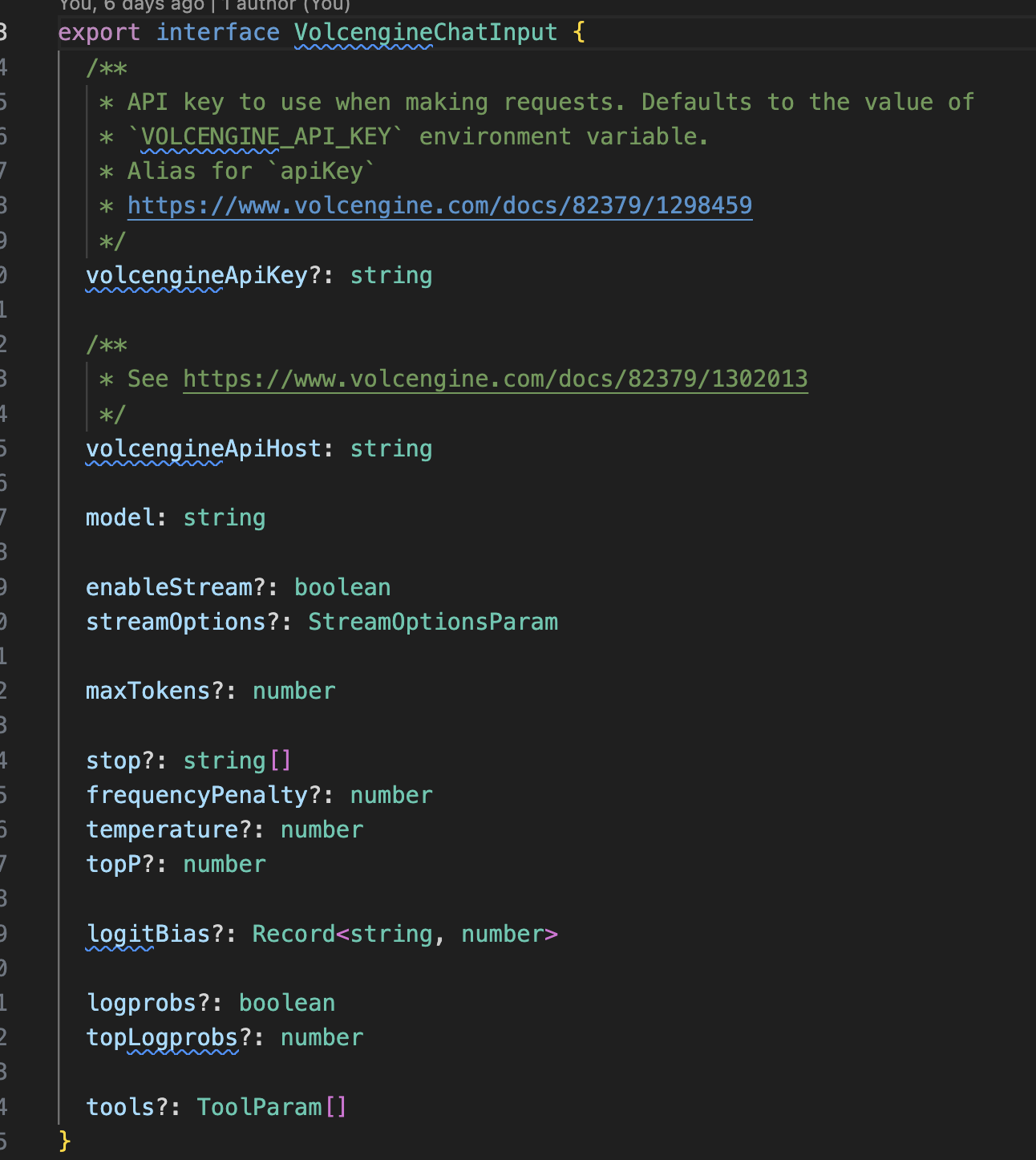
为了提供良好的用户使用体验,并将火山引擎的数据结构用相应的 ts 声明表示,详见
- Open API 请求封装
一般大模型的接口返回都支持流式和非流式,这里我们实现request方法将和大模型 OpenApi 的非流式和流式调用作为统一的封装。将 langchain 的数据结构转化为火山引擎接收的数据结构并调用 Open API
1 | async _request(messages: BaseMessage[], options: this['ParsedCallOptions'], stream?: boolean): Promise<Response> { |
_call方法实现
_call 方法是在模型调用invoke等方法时被调用,返回的是模型返回的字符串回答。我们在该方法下也支持流式调用,如果是流式调用则把流式调用的结果拼接成完整的字符串后再返回
1 | async _call(messages: BaseMessage[], options: this['ParsedCallOptions'], runManager?: CallbackManagerForLLMRun): Promise<string> { |
_streamResponseChunks方法实现
该方法用于大模型交互时流式输出支持,例如调用 model.stream等。
langchain 提供了工具函数convertEventStreamToIterableReadableDataStream。这里我们只需要将调用_request方法返回的响应传递给工具方法即可得到一个IterableReadableDataStream,对该流进行解析即可实现流式返回解析。
每次接收到的数据进行 JSON 序列化后调用ChatGenerationChunk和AIMessageChunk构造出生成器函数的返回对象就完成了整个流式数据的读取。需要注意的是火山引擎流式接口使用 SSE 协议并以[DONE]作为结束标记,在chunk 为 [DONE] 时需要退出流的解析
1 | import { convertEventStreamToIterableReadableDataStream } from '@langchain/core/utils/event_source_parse' |
PS: 对于更加进一步实现模型调用 tracing 等能力,可以实现基类BaseChatModel。
由于这里我们只作为聊天工具使用为了简单起见直接实现的SimpleChatModel,SimpleChatModel本身也是继承自BaseChatModel,只是自带实现了简单版本的abstract _generate(messages: BaseMessage[], options: this["ParsedCallOptions"], runManager?: CallbackManagerForLLMRun): Promise<ChatResult>; 方法
至此,我们即实现了 langchain 对火山引擎大模型的对接,代码验证
1 | import { HumanMessage } from '@langchain/core/messages' |
可见我们这里已经调用火山引擎大模型成功了
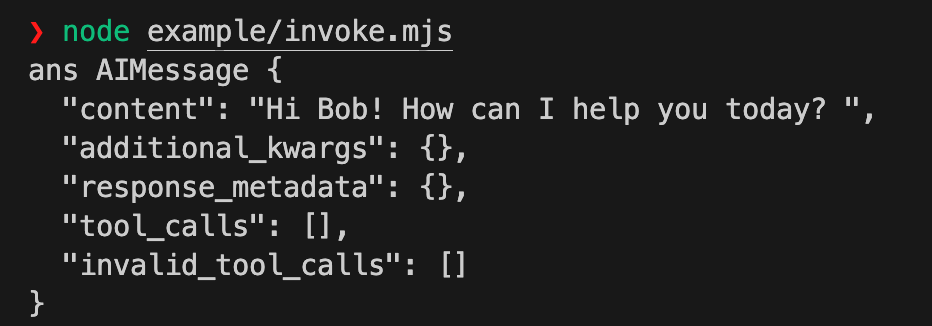
该 langchain 火山引擎大模型集成代码同时发布了 npm 包 langchain-bytedance-volcengine
参考
- Post title:LLM 应用开发入门 - 实现 langchain.js ChatModel 接入火山引擎大模型和实现一个 CLI 聊天机器人(上)
- Post author:flytam
- Create time:2024-08-28 21:17:47
- Post link:https://blog.flytam.vip/LLM 应用开发入门 - 实现 langchain.js ChatModel 接入火山引擎大模型和实现一个 CLI 聊天机器人(上).html
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.